Blockly Serialization: High Level Design
Published 7/24/19
Blockly’s serialization system is one of the most vital (and as a result, sensitive) parts of Blockly. It is what allows the end-user’s blocks (and variables, workspace comments, etc) to be saved, and loaded again when they come back to their project.
The system works in its current state, but it could use a little refactoring. Currently everything is very dependent on XML. All serialization hooks expect and return XML, even the serialization namespace is just called Blockly.Xml. This isn’t a great situation for two reasons:
- JSON would be a better way to store this information. It can store arrays in a more readable format, and it is easier for a human to write.
- It’s not extendable. If a new better format comes along you want to be able to easily move to it, this is definitely not possible with the current system.
I think we can design something better.
Requirements
Before we get started designing something it’s best to have an idea of what we’re designing, so let’s lay out some requirements.
- All serialization hooks need to be format-agnostic. Meaning they shouldn’t need to know if they’re being serialized to xml, or json, or something else. They should always work the same.
- It needs to be easy to add new formats. You shouldn’t need to modify the core, and ideally you would only have to write one or two new classes.
- It needs to be backwards compatible. This is a requirement for all new Blockly features, and especially features dealing with serialization. This is because the Blockly team (and really everyone else) wants Blockly to be able to load even its earliest saves without breaking, so that users don’t lose their projects. That being said we’re going to save this requirement for the end because I have a feeling it’s going to be tricky.
Top level architecture
Now that we have an idea of what we’re building let’s see if anyone has designed this before, and done most of the hard work for us! The two design patterns that are coming to mind are the Builder Pattern and the Interpreter Pattern, so let’s grab our handy-dandy “Design Patterns: Elements of Reusable Object Oriented Software” and see how they work.
It looks like Builder is a creational pattern, while Interpreter is behavioral, so Builder is probably what we want. Let’s see how it’s defined:
Intent: Separate the construction of a complex object…
In our case that complex object would be our workspace filled with blocks.
... from its representation so that the same construction process can create different representations.
So the same system could create a workspace with a bunch of “if” blocks, or a variety of math blocks, or whatever else we want.
The Builder Pattern has two different sets of classes, Directors and Builders. Directors tell Builders how to build something. Builders actually construct the thing.
Directors are often parameterized with some sort of file or object; they then “read” through it, telling the Builder how to build based on what they find. This is how we will be using Directors.
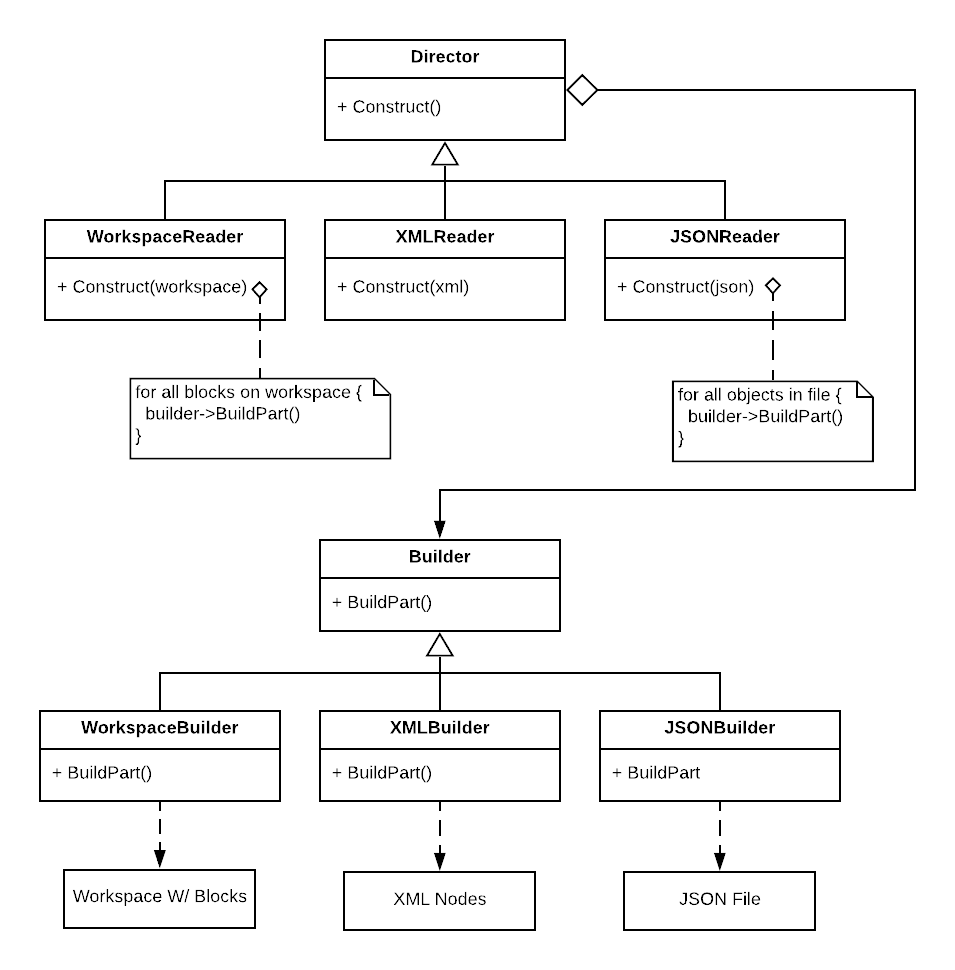
Participants
- Builder
- Specifies an abstract interface for adding parts (blocks, comments, etc) to a workspace or workspace representation.
- ConcreteBuilder
- Constructs and assembles parts of the workspace/workspace representation by implementing the Builder interface.
- Defines and keeps track of what it creates.
- Director
- Defines an interface for constructing an object.
- ConcreteDirector/Reader
- Constructs an object by implementing the Director interface and using the Builder interface.
The interesting thing about this architecture is that the serialization and deserialization are all one system. We can use a WorkspaceReader with an XMLBuilder to serialize to XML, or an XMLReader with a WorkspaceBuilder to deserialize from XML. We can even use an XMLReader with a JSONBuilder to convert from XML to JSON.
Builder API
Now that we have an understanding of the top-level architecture we need to go a level deeper and figure out how our Builder is actually going to work.
What does our Builder need to build?
Our builder needs to be able to build anything that exists on the workspace or on objects inside the workspace (e.g. fields on blocks). As of 1.20190419.0 that means:
- Workspace Comments
- Workspace Variables
- Top Blocks
- Next Blocks
- Input Blocks
- Block State (e.g. isMovable, isDeletable, isShadow, etc)
- Block Field Values
- Block Mutator Values
- Block Comment Values
That should cover everything we currently have to build, but there's something else we need to figure out.
How are we going to traverse?
Blocks on a workspace are like a tree structure.
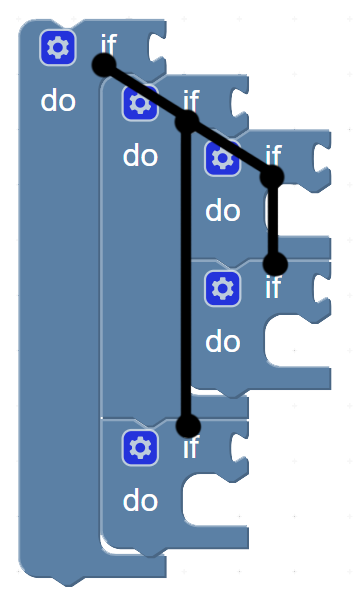
We need a way to traverse this tree as we’re building it.
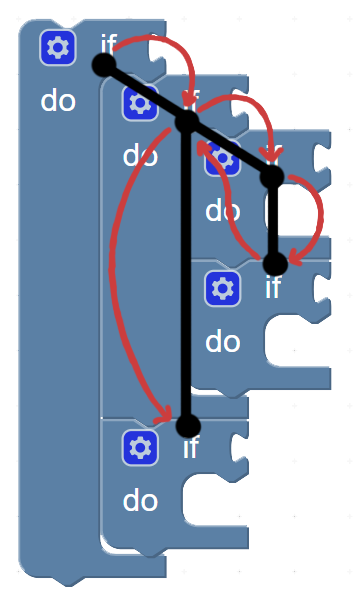
The current system uses recursion to do this.
function blockToXML(block) {
blockNode = new Node(‘block’)
if (block has a child block) {
blockNode.append(blockToXml(child block))
}
// Do other stuff to the blockNode...
return blockNode
}
But we can’t exactly do that with our new Builder Pattern, because we won’t be able to modify the “blockNode” directly.
function serializeBlock(block) {
builder.addBlock(block)
if (block has a child block) {
serializeBlock(block)
}
// Stuck: We can’t access the previous block because the Builder has moved past it.
}
Luckily basically everything you can do with recursion you can also do with stacks (since recursion is just a special kind of stack, a call stack).
The basic system we’ll need to handle traversal will look like this:
- The Builder will save its “position” to a stack every time a new block is added.
- It will have a Restore/GoBack/GoToPrevious method the Director can call to walk back up the tree.
If we want to add other traversal helpers, for example some sort of Tokenization system so we can save arbitrary locations, that can always be added later.
Finalized Builder API
- addVariable(variableObj)
- addComment(commentObj)
- addTopBlock(blockType)
- addNextBlock(blockType)
- addInputBlock(blockType, inputName)
- setBlockShadow(isShadow)
- setBlockMovable(isMovable)
- setBlockDeletable(isDeletable)
- setBlockEditable(isEditable)
- setBlockDisabled(isDisabled)
- setFieldValue(valueObj, fieldName)
- setMutatorValue(valueObj)
- setCommentValue(commentObj)
- goToPrevious()
Serialization hooks
Serialization hooks are places where outside developers can add information to a save in a safe way i.e. a non-hacky way. In our requirements we decided that all of the hooks should be format agnostic. This means no directly manipulating XML, JSON, etc. We’re going to accomplish this by using objects.
We (as of 1.20190419.0) need hooks for the following:
- Serializing mutations.
- Deserializing mutations.
- Serializing fields.
- Deserializing fields.
The way I envision the serialization working is:
- The WorkspaceReader creates an empty object.
- It then passes the object to the serialization hook.
- The hook adds properties to the object to save whatever data it needs to, and then returns it.
- The WorkspaceReader passes the filled object to the Builder.
- The Builder then converts the object into whatever format it needs to.
Deserialization will work in a similar way:
- The Reader converts the XML/JSON back into a JavaScript object.
- It then passes the object to the WorkspaceBuilder.
- The Builder passes the object to the deserialization hook.
- And finally the hook applies the saved data.
The hooks (and builders!) only ever touch JavaScript objects, fulfilling our format-agnostic requirement.
Integrating the system
Now that we’ve designed the system, it’s time to figure out how it’s going to fit into the rest of Blockly.
The first (and obviously most important :P ) thing you need to do when creating a new system, is give it a namespace. After much debate I’ve settled on Blockly.serialization as the stand-in name.
With that challenging task completed we can start figuring out what it’s actually going to do. Let’s start with the two functions we know we’ll need:
loadWorkspaceSaveData(save, workspace)saveWorkspace(workspace)
To keep the system flexible loadWorkspaceSaveData will need to be
able to load saves of any format. To do that it will need to be able
to detect the format, and pick the right reader.
It seems like we need a
registerReader(detectorString, readerConstructor) function.
Now when loadWorkspaceSaveData gets called it
can figure out which ‘detectorString’ is at the top of the save, and pick
the reader registered with that string.
Next we’ll need to be able to specify which format we want
the workspace to save to. Looks like we’ll need another function
called registerBuilder(formatString, builderConstructor).
Then we just need to redefine saveWorkspace as
saveWorkspace(workspace, formatString) so that it can pick the
correct builder based on the formatString it gets passed.
This gives us a finalized serialization API of:
loadWorkspaceSaveData(save, workspace)saveWorkspace(workspace, formatString)registerReader(detectorString, readerConstructor)registerBuilder(formatString, builderConstructor)
Backwards compatibility
We’ve done it. We’ve built a simple, elegant, extensible system. But now we’ve got to make it bend and twist around the old system so that nobody breaks… here we go!
Firstly I think we should set up a simple rule: If it was serialized with the old system, the old system deserializes it. If it was serialized with the new system, the new system deserializes it.
Each system will then gives its hooks priority. E.g. if the old system runs into a block with new hooks and old hooks, it will use the old hooks. This will make sure we don’t send data generated by an old hook to a new hook, or vise versa.
Next the systems need a way to serialize blocks that don’t have their hooks. For example, the old system needs a way to serialize a block that only has new hooks. The following chart shows how this logic will work:
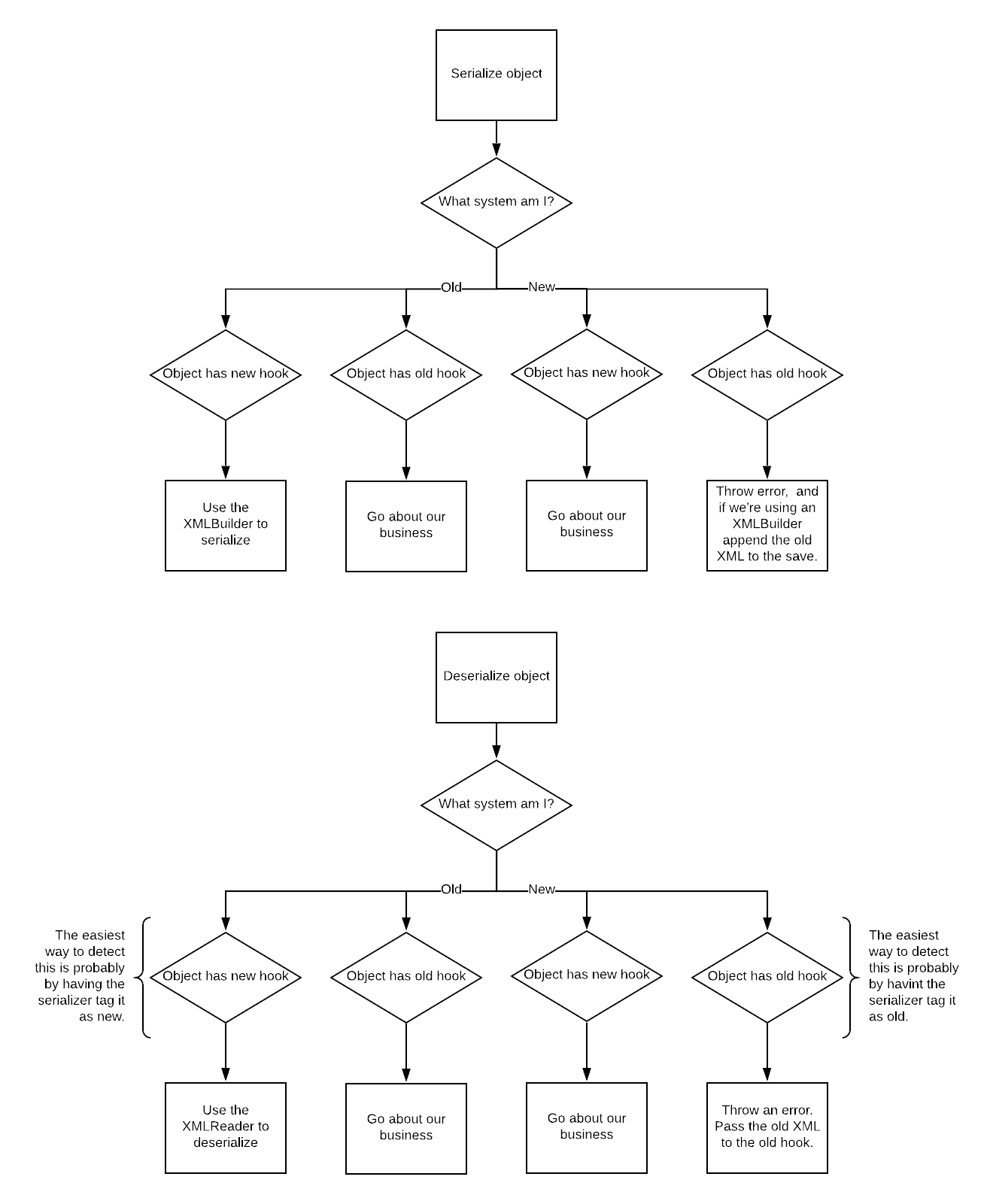
In short, the two systems will be able to hook into each other. If one of them runs into a hook it can't handle, it will just pass it off to the other system.
Now that both systems have been joined together we should be able to handle whatever outside developers want to do.
Conclusion
Now there are some areas related to serialization that weren’t covered here (e.g. dynamic categories, mutator workspaces, and workspace diffing) but I think this is a good starting point for refactoring the serialization system.